官网介绍
scikit-learn: machine learning in Python
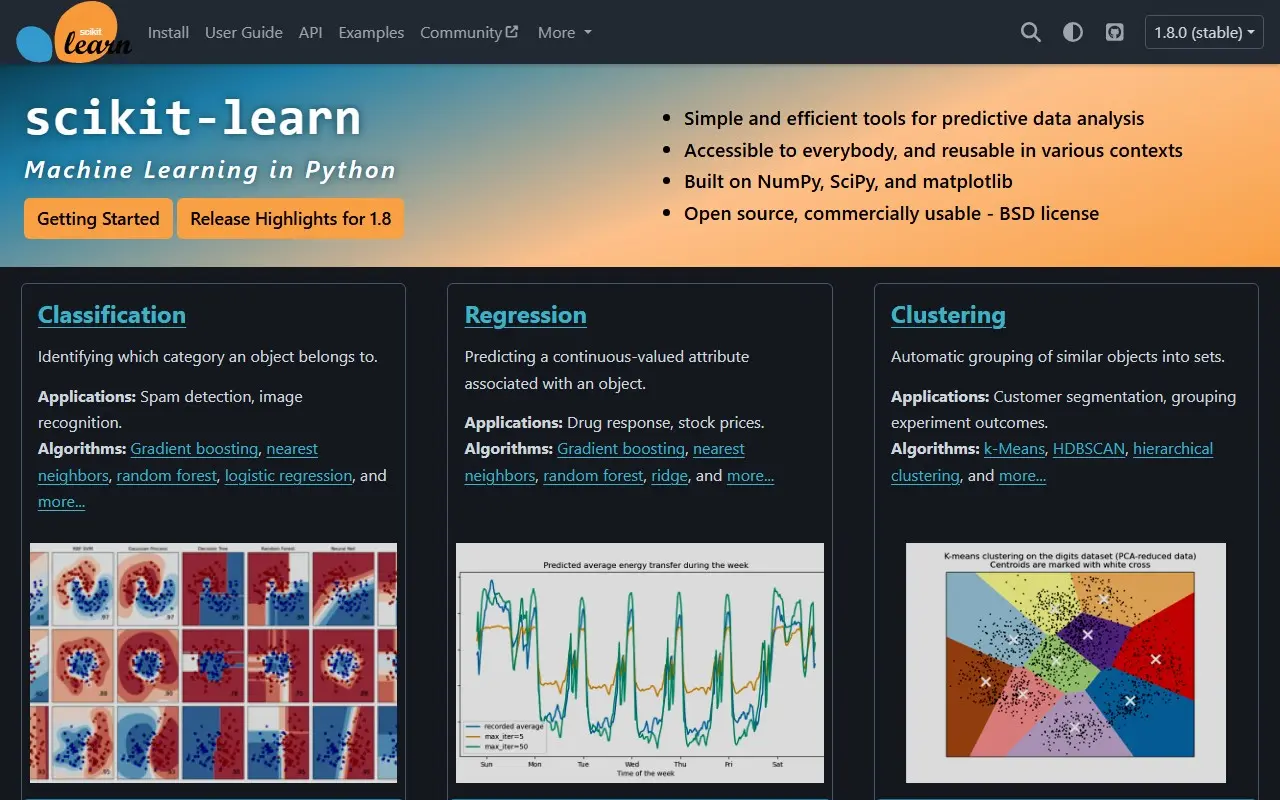
scikit-learn是一个基于Python的机器学习库,当前最新版本为1.8.0,1.9版本正在开发中。它提供了简单而高效的预测数据分析工具,设计目标是让所有人都能使用,并能在各种环境中重用。scikit-learn构建在NumPy、SciPy和matplotlib等Python科学计算库之上,采用BSD开源许可证,可用于商业用途。该项目由活跃的社区开发和维护,拥有广泛的用户群体和贡献者网络。

核心功能特点
分类
识别对象所属的类别。提供多种算法,包括梯度提升、最近邻、随机森林、逻辑回归等,可应用于垃圾邮件检测、图像识别等场景。
回归
预测与对象相关的连续值属性。包含梯度提升、最近邻、随机森林、岭回归等算法,适用于药物反应预测、股票价格预测等领域。
聚类
将相似对象自动分组。提供k-Means、HDBSCAN、层次聚类等算法,可用于客户细分、实验结果分组等应用场景。
降维
减少要考虑的随机变量数量。包括PCA、特征选择、非负矩阵分解等方法,有助于数据可视化和提高计算效率。
模型选择
比较、验证和选择参数和模型。提供网格搜索、交叉验证、 metrics等工具,通过参数调优提高模型准确性。
预处理
特征提取和标准化。提供数据预处理和特征提取工具,可将输入数据(如文本)转换为适合机器学习算法使用的格式。
应用场景
- 垃圾邮件检测:利用分类算法识别和过滤垃圾邮件,提高邮件系统效率和用户体验。
- 图像识别:通过分类技术对图像内容进行识别和分类,应用于安防监控、医学影像分析等领域。
- 药物反应预测:使用回归模型预测药物对患者的反应,辅助医生制定个性化治疗方案。
- 股票价格预测:利用回归分析预测股票价格走势,为投资者提供决策参考。
- 客户细分:通过聚类算法将客户分成不同群体,帮助企业制定精准营销策略。
- 实验结果分组:使用聚类技术对实验数据进行分组分析,发现数据中的隐藏模式和规律。
- 数据可视化:通过降维技术将高维数据转换为低维表示,便于数据探索和模式识别。
- 文本数据处理:通过预处理技术将文本数据转换为机器学习算法可理解的格式,应用于情感分析、文本分类等任务。
优势
scikit-learn的主要优势在于其简单易用性和高效性能的平衡,为用户提供了丰富多样的机器学习算法,覆盖了从数据预处理到模型评估的完整工作流程。作为开源项目,它拥有活跃的社区支持和持续的开发更新,确保了技术的前沿性和问题的快速解决。基于NumPy、SciPy和matplotlib构建,使其与Python科学计算生态系统无缝集成,为用户提供一致的编程体验。BSD许可证允许商业使用,降低了企业采用的法律障碍,同时丰富的文档和示例资源加速了用户的学习曲线。
价值总结
scikit-learn的核心价值在于降低了机器学习技术的使用门槛,使数据分析人员和开发人员能够快速构建和部署高质量的机器学习模型。通过提供统一的API和丰富的算法库,它简化了复杂机器学习任务的实现过程,帮助用户将精力集中在问题解决而非工具学习上。无论是学术研究还是商业应用,scikit-learn都能提供可靠、高效的解决方案,帮助用户从数据中提取有价值的见解,做出更明智的决策。其开源特性不仅降低了使用成本,还促进了知识共享和技术创新,为用户创造了长期价值。
用户体验与优势
用户使用scikit-learn的体验以简洁直观为特点,其一致的API设计使不同算法的学习和切换变得简单。许多用户反馈scikit-learn具有快速的学习曲线,使高级数据分析在Python中变得对任何人都可及。用户赞赏其易用性、性能和实现的算法多样性,认为这些特性使其成为数据科学工作流程中不可或缺的工具。通过提供从数据预处理到模型评估的完整工具链,scikit-learn支持用户完成端到端的机器学习项目,减少了不同工具间切换的开销,提高了工作效率。
技术优势
技术层面上,scikit-learn基于NumPy、SciPy和matplotlib等成熟的科学计算库构建,确保了底层数值计算的高效性和稳定性。其模块化设计使代码具有良好的可维护性和可扩展性,便于新算法和功能的集成。scikit-learn注重算法的实现质量,许多核心算法经过优化,能够处理大规模数据集。项目遵循严格的开发规范和测试流程,确保了代码的可靠性和稳定性。持续的版本更新和活跃的社区贡献保证了技术的持续演进,使scikit-learn能够及时吸收最新的机器学习研究成果,为用户提供前沿的分析工具。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3