官网介绍
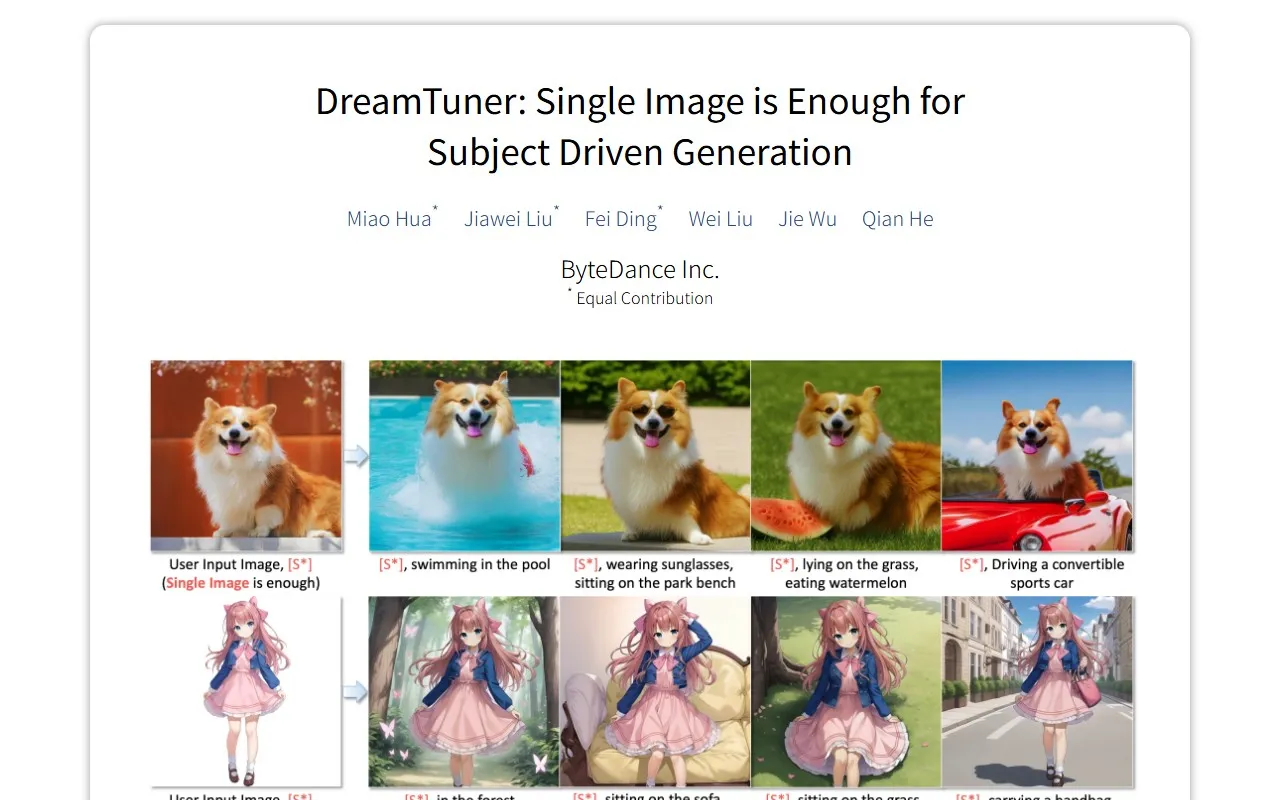
DreamTuner 是由 ByteDance Inc. 开发的一种创新的主题驱动图像生成方法,其核心优势在于仅需单张参考图像即可实现高质量的个性化内容生成。该方法针对现有扩散模型在主题驱动生成中存在的主题学习与模型生成能力权衡问题,以及图像编码器压缩导致细节丢失等挑战,提出了从粗到精的主题信息注入机制。DreamTuner 结合了主题编码器预训练、主题驱动微调及推理三个阶段,通过主题编码器实现粗粒度主题身份保留,通过自主题注意力实现细粒度细节保留,同时与 ControlNet 结合支持姿势等多条件控制,最终在文本或姿势等条件下生成高度保真且细节丰富的个性化图像。

核心功能特点
单图像主题驱动生成
仅需一张参考图像即可完成模型微调,实现特定主题的个性化生成。相比传统方法需要多张图像的要求,大幅降低了数据采集门槛,使普通用户也能轻松创建专属主题内容。
粗到精的主题身份保留机制
通过主题编码器与自主题注意力的协同作用,从两个层次保留主题身份:主题编码器提供压缩的粗粒度主题特征,通过额外注意力层注入生成过程;自主题注意力基于原始自注意力层,利用参考图像的高分辨率特征实现细粒度细节保留,确保生成图像既符合主题整体特征,又不丢失关键细节。
自主题注意力即插即用设计
自主题注意力是一种无需训练的改进机制,通过修改原始自注意力层,将生成图像特征作为查询,生成与参考图像特征的拼接作为键和值,可在推理阶段直接使用,作为插件式解决方案提升生成质量,无需额外训练成本。
与 ControlNet 结合的多条件控制
支持与预训练 ControlNet 结合,实现布局、姿势等多条件控制。在微调阶段引入冻结的 ControlNet 提供参考图像布局,使主题编码器更专注于主题内容;推理阶段可利用 ControlNet 控制生成图像的姿势、场景结构等,扩展生成的可控性。
细粒度细节保留能力
通过自主题注意力机制,参考图像特征与生成图像特征共享相同分辨率和数据分布,确保注入的细节信息精确。同时利用显著目标检测(SOD)模型生成前景掩码,消除背景干扰,重点保留主题的纹理、图案、标志等关键细节(如宠物头部条纹、物品上的文字和logo)。
改进的分类器-free引导策略
提出融合参考图像引导的改进分类器-free引导方法,通过调整参考图像和条件的引导权重,平衡主题保留与文本/条件一致性,提升生成图像与输入条件的匹配度,同时增强主题特征的稳定性。
应用场景
- 动漫角色生成与编辑:支持动漫角色的表情编辑(如张嘴、哭泣、大笑)和场景迁移(如坐在沙发上、公园长椅上),保持角色身份一致性,满足二次元创作需求。
- 自然图像主题生成:针对宠物(如狗)、日常物品(如花瓶、背包、运动鞋、罐头)等自然图像主题,实现跨场景迁移(如丛林、雪地、海滩背景),保留主题细节特征。
- 姿势控制角色生成:结合 ControlNet 实现角色姿势控制,通过单张参考图像微调后,可根据目标姿势生成新图像,支持多帧连贯生成(如动画序列),确保帧间主题一致性。
- 个性化主题编辑:对特定主题进行局部或全局编辑,如修改表情、动作、场景背景,无需重新训练模型,快速生成多样化衍生内容。
- 跨场景主题迁移:将同一主题(如背包、运动鞋)迁移到不同场景(雪地、海滩、城市背景),保持主题外观一致性,适用于广告、电商产品展示等场景。
- 个性化内容创作:为社交媒体、游戏、影视等领域提供个性化角色/物品生成,用户仅需上传一张参考图即可生成符合特定风格或场景的内容,降低创作门槛。
- 商业产品可视化:帮助商家快速生成产品在不同场景下的展示图(如罐头在雪地、海滩的效果),无需实际拍摄,节省营销素材制作成本。
- 多帧动画生成:通过结合参考图像和前一帧生成图像的自主题注意力,实现多帧动画的连贯生成,确保角色在运动过程中的身份和细节一致性。
优势
DreamTuner 的核心优势在于其创新的"单图像即可微调"机制与"粗到精"的主题保留策略。相比现有方法,它仅需一张参考图像即可完成个性化微调,大幅降低了数据需求;通过主题编码器与自主题注意力的协同,既解决了传统微调中模型生成能力退化的问题,又克服了图像编码器压缩导致的细节丢失;自主题注意力的即插即用设计使其在推理阶段无需额外训练即可提升效果;与 ControlNet 的结合扩展了多条件控制能力,支持姿势、布局等精确控制;改进的引导策略进一步平衡了主题保留与条件一致性,整体生成质量与细节保真度处于行业领先水平。
价值总结
DreamTuner 的核心价值在于为用户提供了低门槛、高质量、高可控的个性化图像生成解决方案。对普通用户,它降低了个性化内容创作的技术门槛,仅需单张图像即可生成多样化主题内容;对专业创作者,它提升了工作效率,减少了数据采集和模型训练成本;对企业用户,它支持快速的产品可视化和营销素材生成,节省拍摄与设计费用。其细节保留能力和多条件控制特性,扩展了个性化生成的应用边界,使主题驱动创作从"可能"走向"高效且高质量",为数字内容创作领域带来了新的可能性。
用户体验与优势
DreamTuner 为用户带来了简洁高效的使用体验。用户仅需上传一张参考图像,即可通过简单微调获得专属主题模型,无需专业的机器学习知识;生成过程支持文本描述、姿势等多种控制条件,用户可直观地调整生成效果;细节保留能力确保生成图像与参考主题高度一致,避免了传统方法中常见的"主题漂移"问题;自主题注意力的即插即用特性意味着用户在推理阶段可灵活启用或调整细节保留强度,满足不同场景需求。整体流程简单直观,生成效果可控性强,让用户能够快速将创意转化为高质量图像内容。
技术优势
DreamTuner 在技术层面具有多项创新:其一,提出主题编码器与冻结 ControlNet 的协同训练机制,通过 ControlNet 提供布局信息,使编码器专注于主题内容,实现粗粒度身份保留;其二,设计自主题注意力机制,利用参考图像与生成图像共享分辨率的特征,结合 SOD 模型消除背景干扰,实现细粒度细节保留,且无需额外训练;其三,改进分类器-free 引导策略,融合参考图像引导与条件引导,平衡主题保留与条件一致性;其四,通过扩散前向过程使参考图像特征与生成图像特征共享数据分布,确保注入信息的有效性;其五,引入调整系数和掩码策略,灵活控制参考图像的影响强度,提升生成稳定性。这些技术创新共同构成了 DreamTuner 在主题驱动生成领域的核心竞争力。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3