官网介绍
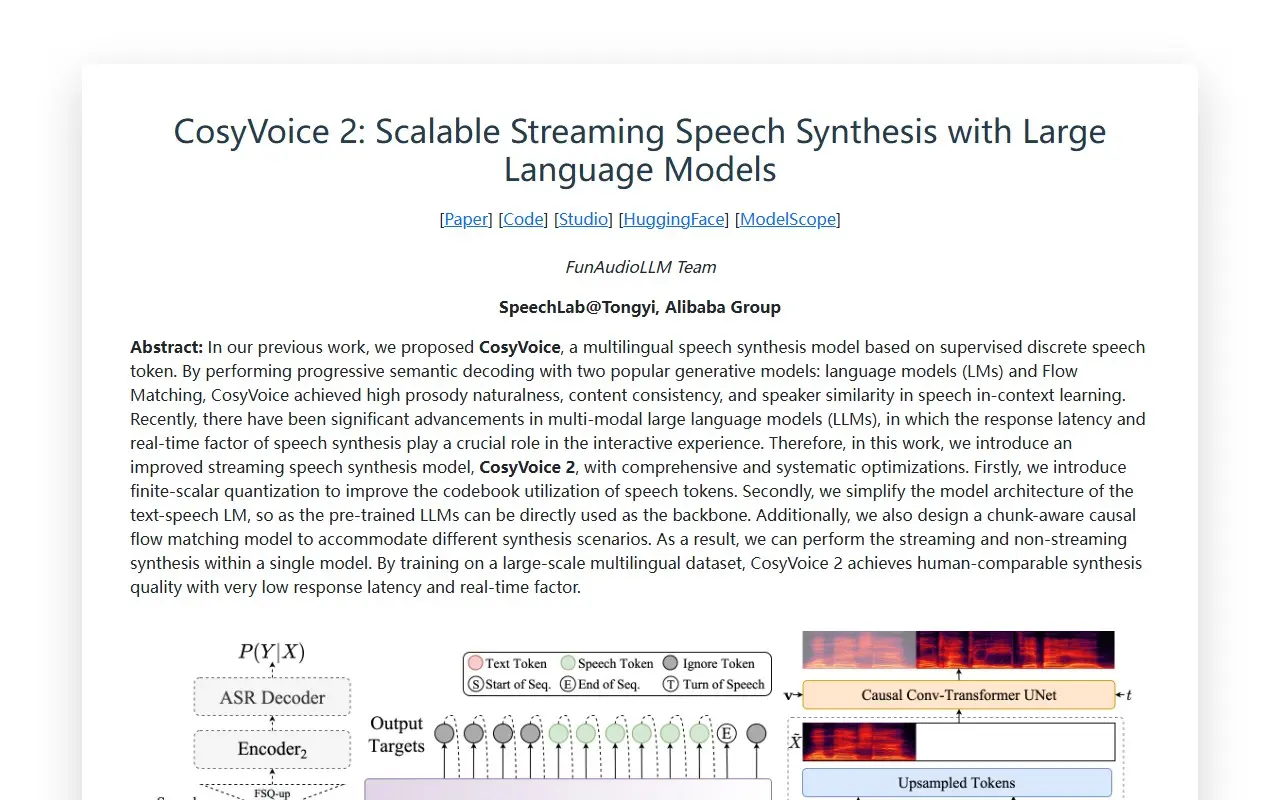
CosyVoice 2.0是由阿里巴巴集团旗下SpeechLab@Tongyi的FunAudioLLM团队开发的新一代语音合成模型,全称为"CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models"。作为CosyVoice 1.0的升级版本,它是一个基于监督离散语音令牌的多语言语音合成模型,通过语言模型(LMs)和流匹配(Flow Matching)两种流行的生成模型进行渐进式语义解码,在语音上下文学习中实现了高韵律自然度、内容一致性和说话人相似度。
CosyVoice 2.0针对多模态大型语言模型(LLMs)交互体验中的响应延迟和实时性问题,进行了全面系统的优化,实现了人类可比的合成质量,同时具有极低的响应延迟和实时因子。该模型支持多种访问方式,包括论文、代码库、在线演示平台、HuggingFace和ModelScope等。

核心功能特点
超低延迟
CosyVoice 2.0引入了集成离线和流式建模的大规模语音生成模型技术,支持双向流式语音合成。首包合成延迟可低至150ms,同时保持最小的质量损失,为实时交互提供了强大支持。
高精度
相比CosyVoice 1.0,CosyVoice 2.0将合成音频中的发音错误减少了30%至50%。在Seed-TTS评估集的困难测试集上,它实现了当前最低的字符错误率,显著提升了语音合成的准确性和可靠性。
强稳定性
CosyVoice 2.0确保零样本语音生成和跨语言语音合成中出色的音色一致性。与1.0版本相比,它在跨语言合成方面表现出显著改进,能够稳定处理不同语言间的语音转换需求。
自然体验
CosyVoice 2.0合成音频的韵律、音质和情感对齐较1.0版本有显著提升,MOS评估分数从5.4提高到5.53(商业化大规模语音合成模型的分数为5.52)。此外,它还升级了可控音频生成能力,支持更精细的情感控制和方言口音调整。
多语言支持
支持零样本上下文生成、跨语言上下文生成和混合语言上下文生成,可处理中文、英文、日文、韩文等多种语言,满足全球化应用需求。
情感与风格控制
提供情感丰富的语音生成能力,支持快乐、悲伤、惊讶、愤怒等多种情感表达,同时支持角色扮演、方言控制、细粒度控制和说话风格控制,满足多样化的语音合成需求。
应用场景
- 智能助手:为各类智能设备提供自然、流畅的语音交互能力,提升用户体验
- 有声内容创作:快速将文字内容转换为高质量有声读物、播客等音频内容
- 多语言客服:支持多语言、跨语言的智能客服语音系统,提升国际客户服务质量
- 影视动画配音:为影视、动画、游戏等内容提供高质量配音,支持多种情感和风格
- 教育领域:生成多语言、多风格的教学音频,支持语言学习和特殊教育需求
- 无障碍服务:为视障人士提供高质量的文本转语音服务,提升信息获取便利性
- 虚拟主播/数字人:为虚拟主播、数字人提供自然、生动的语音生成能力
- 广告营销:生成具有情感吸引力的广告语音,提升营销效果
优势
CosyVoice 2.0的主要优势体现在四个方面:首先是性能卓越,150ms的超低延迟确保了实时交互的流畅性,而5.53的MOS评分已达到商业化大规模语音合成模型水平;其次是多语言支持能力强,不仅支持多种语言的独立合成,还能实现跨语言和混合语言的语音生成;第三是控制能力精细,提供从情感表达、方言口音到说话风格的全方位控制;最后是稳定性高,在零样本和跨语言场景下保持出色的音色一致性,显著降低了发音错误率。这些优势共同构成了CosyVoice 2.0的核心竞争力,使其在语音合成领域处于领先地位。
价值总结
CosyVoice 2.0为用户带来多方面的核心价值:对于开发者,它提供了高性能、低延迟的语音合成解决方案,支持多语言和多样化的语音控制需求;对于企业用户,它能够提升产品的语音交互体验,拓展多语言市场,降低语音内容制作成本;对于终端用户,它提供了更自然、更准确、更具情感的语音体验,满足不同场景下的个性化需求。总体而言,CosyVoice 2.0通过技术创新,弥合了文本与语音之间的鸿沟,为各类语音交互应用提供了强大支持,推动了人机交互向更自然、更智能的方向发展。
用户体验与优势
CosyVoice 2.0在用户体验方面实现了全面提升。首先,超低的150ms首包延迟确保了实时交互的流畅性,用户无需长时间等待即可获得语音响应。其次,发音错误率降低30%至50%,显著提升了语音内容的可理解性和准确性。第三,MOS评分达到5.53的高质量语音输出,使合成语音更加自然、悦耳。此外,增强的情感表达和风格控制能力让用户能够根据需求定制语音特征,满足个性化需求。多语言支持能力也为国际用户提供了便利,特别是在跨语言和混合语言场景下表现出色。总体而言,CosyVoice 2.0通过技术优化,为用户带来了更快、更准、更自然、更多样化的语音合成体验。
技术优势
CosyVoice 2.0在技术层面具有多项显著优势:首先,引入有限标量量化技术,有效提高了语音令牌的码本利用率;其次,简化了文本语音LM的模型架构,使预训练LLMs可以直接用作主干,提升了模型效率和性能;第三,设计了块感知因果流匹配模型,能够适应不同的合成场景,实现单一模型支持流式和非流式合成;第四,通过大规模多语言数据集训练,提升了模型的语言适应性和泛化能力;最后,优化的模型结构和算法使CosyVoice 2.0在保持高质量合成的同时,实现了150ms的超低延迟。这些技术创新共同构成了CosyVoice 2.0的核心竞争力,使其在语音合成的质量、效率和多功能性方面达到了新的高度。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3