官网介绍
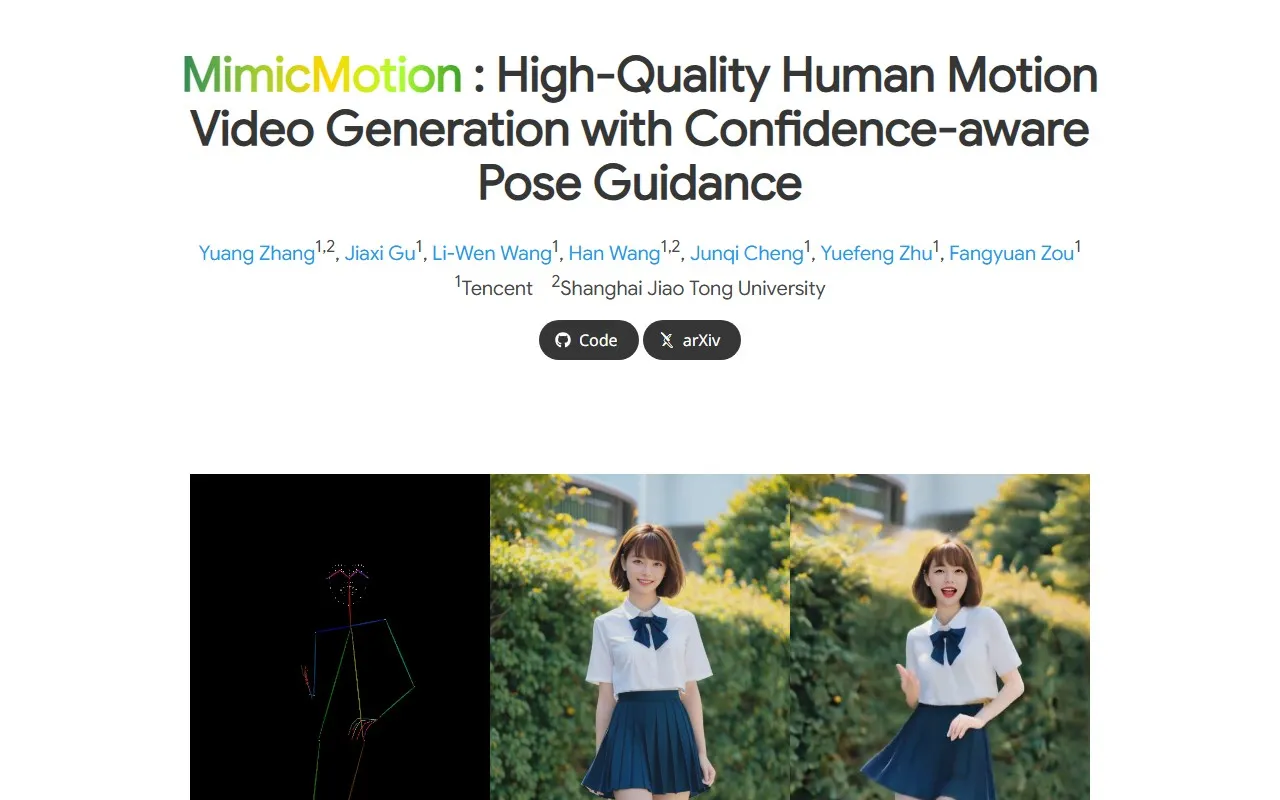
MimicMotion是由腾讯和上海交通大学联合开发的高质量人体动作视频生成框架,全称为"High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance"。该框架能够基于参考图像和姿态序列生成任意长度的高质量视频,解决了传统视频生成在可控性、视频长度和细节丰富度等方面面临的挑战。通过置信感知姿态引导、区域损失放大和渐进式潜变量融合等创新技术,MimicMotion在视频生成质量、时间平滑性和模型鲁棒性方面取得了显著提升。

核心功能特点
置信感知姿态引导
姿态序列伴随关键点置信度分数,使模型能够根据分数自适应调整姿态引导的影响。通过在姿态引导帧上利用亮度表示姿态估计的置信度水平,模型可以增强对错误引导信号的生成鲁棒性,并提供可见性提示以解决姿态模糊问题。
区域特定手部优化器
实现基于置信度阈值生成掩码的策略,对置信度分数超过预定义阈值的区域进行处理,识别可靠区域。在计算视频扩散模型的损失时,对未掩码区域的损失值进行一定比例的放大,使其在模型训练中比其他掩码区域发挥更大作用,有效减少手部失真并增强视觉吸引力。
渐进式潜变量融合
提出用于生成具有时间平滑性的长视频的渐进式方法。在每个去噪步骤中,首先使用训练好的模型分别对视频片段进行去噪,以相同的参考图像和相应的姿态子序列为条件。在每个去噪步骤中,重叠帧根据其帧位置进行渐进式融合,确保长视频生成的时间平滑性。
重叠扩散生成任意长度视频
通过重叠扩散技术,MimicMotion能够生成任意长度的视频。在资源消耗可接受的情况下,实现了视频长度的灵活控制,满足不同场景下的视频生成需求。
基于预训练SVD的模型结构
模型结构基于预训练的SVD (Stable Video Diffusion),在现有强大基础模型上进行优化和创新,既保证了模型性能,又加快了训练和推理速度。
应用场景
- 舞蹈视频创作:能够根据参考图像和舞蹈动作序列生成高质量舞蹈视频,为舞蹈创作者提供灵感和辅助工具
- 虚拟偶像动画:为虚拟偶像生成自然流畅的动作视频,应用于直播、短视频和娱乐内容创作
- 社交媒体内容制作:快速生成符合特定动作要求的创意视频,满足TikTok、Instagram等平台的内容需求
- 影视特效制作:辅助生成复杂的人体动作镜头,降低影视制作成本,提高特效制作效率
- 游戏角色动画:为游戏角色生成逼真的动作序列,丰富游戏交互体验
- 健身指导视频:根据标准动作生成详细的健身指导视频,帮助用户正确学习健身动作
- 教育培训:用于生成教学演示视频,特别是需要展示特定动作和姿势的技能培训领域
- 动作捕捉辅助:作为动作捕捉技术的补充,快速将动作序列转化为可视化视频,辅助动画制作流程
优势
MimicMotion相比现有方法具有多方面显著优势。在定量评估中,该方法在FID-VID和FVD指标上均优于MagicPose、Moore和MuseV等现有方法,实现了9.3的FID-VID值和594的FVD值,显著领先于其他对比方法。在手部生成质量方面表现尤为突出,能够更准确地遵循参考姿势,即使未在TikTokDataset上进行训练,也能在该数据集的测试集上取得优异表现。用户研究表明,相比基线方法,用户更偏好MimicMotion生成的结果。该方法能够生成任意长度的视频,同时保持时间平滑性和高质量的细节表现,在资源消耗和生成效果之间取得了良好平衡。
价值总结
MimicMotion的核心价值在于解决了视频生成领域长期存在的可控性、视频长度和细节丰富度等关键挑战。通过创新的置信感知姿态引导技术,模型能够自适应调整姿态引导的影响,提高生成结果的准确性和可靠性。区域损失放大技术有效减少了图像失真问题,特别是在手部等关键区域的生成质量上有显著提升。渐进式潜变量融合策略使得生成任意长度的平滑视频成为可能,同时保持了可接受的资源消耗。这些技术创新不仅推动了视频生成技术的发展,也为内容创作、教育培训、娱乐媒体等多个领域提供了强大的工具支持,具有广泛的应用前景和商业价值。
用户体验与优势
MimicMotion在用户体验方面表现出色,通过直观的姿态引导机制,用户可以轻松控制视频生成过程。生成的视频具有更高的视觉质量和时间连贯性,减少了传统方法中常见的动作跳跃和纹理不稳定问题。用户研究表明,在TikTokDataset测试集上,用户对MimicMotion的偏好明显高于其他对比方法。模型能够准确理解并遵循参考姿态,生成的视频更符合用户预期,减少了反复调整和生成的需要。此外,任意长度视频生成功能为用户提供了更大的创作自由度,满足不同场景下的视频长度需求,从短视频到长视频均能保持一致的高质量表现。
技术优势
MimicMotion在技术层面具有多项创新优势。首先,置信感知姿态引导机制使模型能够根据姿态估计的置信度自适应调整引导强度,增强了对错误引导信号的鲁棒性,并提供可见性提示以解决姿态模糊问题。其次,区域损失放大技术通过对高置信度区域的损失值进行放大,显著减轻了图像失真,特别是在手部等关键区域的生成质量上有明显提升。第三,渐进式潜变量融合策略通过在去噪过程中对重叠帧进行渐进式融合,有效保证了长视频生成的时间平滑性。最后,基于预训练SVD的模型结构不仅加速了模型开发进程,也保证了模型在各种场景下的稳定性和泛化能力。这些技术创新共同构成了MimicMotion的核心竞争力,使其在定量指标和定性效果上均超越了现有方法。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3