官网介绍
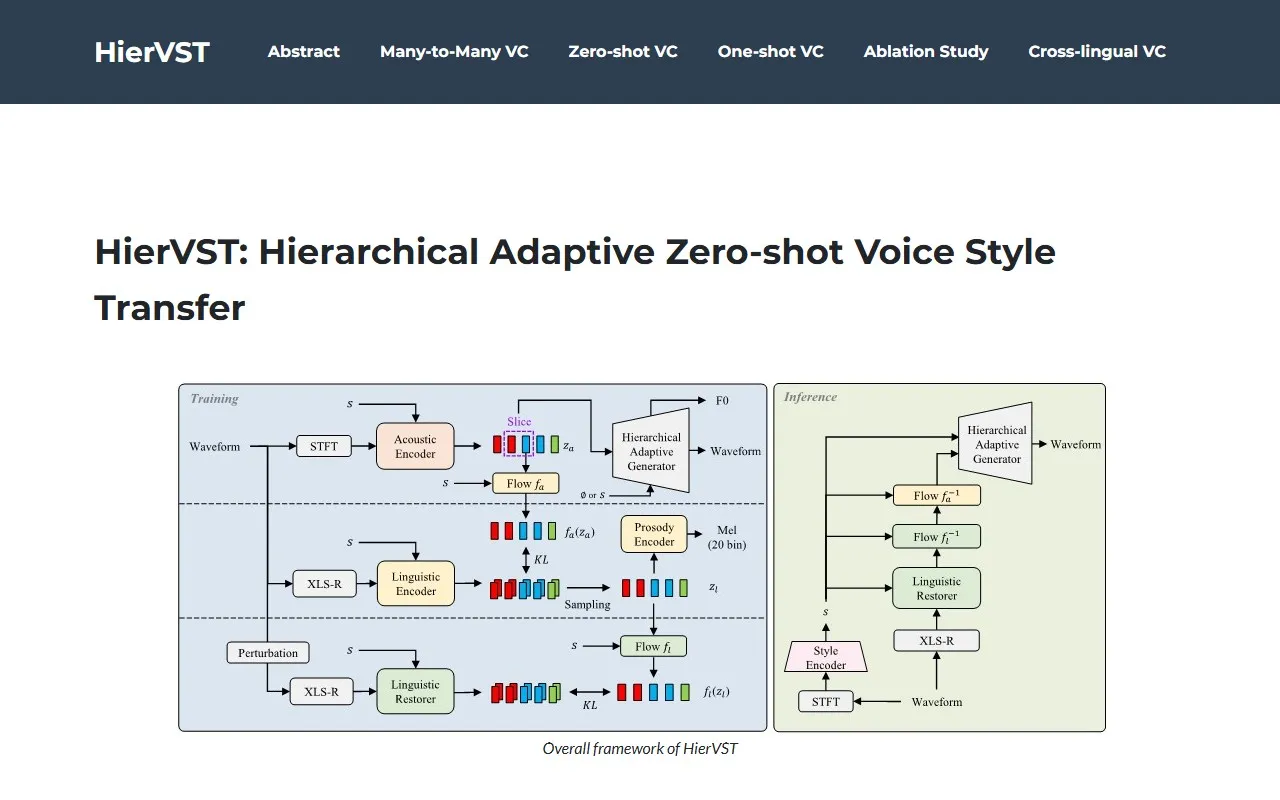
HierVST是一款名为"Hierarchical Adaptive Zero-shot Voice Style Transfer"(分层自适应零样本语音风格转换)的先进语音转换模型。该模型专注于解决现有零样本语音风格转换系统中难以转换新说话者语音风格的问题,提出了一种分层自适应的端到端解决方案。HierVST无需任何文本转录,仅使用语音数据集进行训练,通过分层变分推理和自监督表示技术实现高质量的语音转换。其创新的分层自适应生成器能够依次生成音高表示和波形音频,同时利用无条件生成提高声学表示中的说话人相关声学能力。通过分层自适应结构,模型能够适应新的语音风格并逐步转换语音,在零样本语音风格转换场景中表现优于其他现有模型。

核心功能特点
零样本语音转换
HierVST具备强大的零样本语音转换能力,能够处理训练期间未见的说话者语音风格转换。在VCTK等数据集上的实验表明,即使面对完全未见过的说话者,模型也能实现高质量的语音转换,突破了传统语音转换模型对已知说话者的依赖限制。
分层自适应生成
采用创新的分层自适应生成器结构,能够分阶段依次生成音高表示和波形音频。这种分层设计使模型能够逐步转换语音特征,先捕捉高层风格特征,再生成细节波形,从而实现更自然、更准确的语音风格迁移。
多对多语音转换
支持灵活的多对多语音转换功能,在LibriTTS等数据集上验证了其在多种说话者组合之间的转换能力。无论是男性转女性、女性转男性还是同性之间的语音转换,都能保持较高的自然度和风格相似度。
少样本快速适应
具备高效的少样本学习能力,仅需单个样本进行微调即可快速适应新的语音风格。实验结果显示,通过少量微调迭代(如100-1500次迭代),模型就能显著提升对特定说话者风格的捕捉能力,实现更精准的个性化语音转换。
跨语言语音转换
支持跨语言语音转换功能,能够处理不同语言之间的语音风格迁移。在CSS10多语言数据集上的实验验证了其在法语、匈牙利语、希腊语、芬兰语、荷兰语、俄语、西班牙语和德语等多种语言组合间的转换能力,为多语言语音应用提供了强大支持。
无需文本转录的训练方式
采用无需文本转录的训练方法,仅使用语音数据集即可完成模型训练。这一特点大大降低了数据收集的难度和成本,同时避免了因文本转录错误可能带来的负面影响,使模型能够更直接地从语音信号中学习风格特征。
应用场景
- 语音助手个性化:为智能语音助手提供个性化语音风格,用户可选择喜爱的声音风格作为语音助手的输出声音,提升用户体验和产品竞争力。
- 有声内容创作:在有声书、播客等内容创作中,作者或制作人可利用HierVST将自己的声音转换为不同风格,无需聘请专业配音演员即可制作多角色有声内容,降低制作成本。
- 影视游戏配音:在影视后期制作和游戏开发中,可用于角色配音的快速调整和多版本制作,实现同一台词的多种语音风格表现,提高配音效率和灵活性。
- 语音无障碍辅助:为语言障碍患者提供语音辅助,将文字转换为自然的语音输出,或帮助患者将自己的声音转换为更清晰、更容易理解的语音,改善沟通能力。
- 多语言语音交互系统:在国际业务或多语言环境中,用于构建支持多种语言和口音的语音交互系统,实现跨语言沟通中的自然语音转换,提升国际用户体验。
- 语音娱乐应用:在语音聊天软件、在线游戏等娱乐场景中,为用户提供实时语音风格转换功能,增加社交趣味性和互动性,如变声聊天、角色扮演等。
- 语音数据增强:为语音识别、说话人识别等语音技术的训练提供丰富的合成语音数据,通过转换现有语音数据的风格生成新的训练样本,提升模型的泛化能力。
- 个性化语音消息:用户可将自己的语音消息转换为不同风格发送给联系人,如模仿名人声音、变换性别或年龄特征等,增加消息传递的趣味性和个性化表达。
优势
HierVST在语音转换领域展现出多方面的显著优势。与AutoVC、VoiceMixer、DiffVC、Speech Resynthesis和YourTTS等现有模型相比,HierVST在零样本语音转换场景中表现出更优的性能。其分层自适应结构使模型能够更好地适应新的语音风格并逐步转换语音特征,解决了传统模型在处理未见说话者时效果不佳的问题。模型无需文本转录的训练方式降低了数据依赖和预处理复杂度,同时分层变分推理和自监督表示技术的应用提升了特征学习的效率和质量。此外,HierVST不仅支持零样本转换,还具备少样本快速适应能力和跨语言转换能力,展现出比单一功能语音转换模型更广泛的适用性和更强的场景适应性。
价值总结
HierVST的核心价值在于其突破了传统语音转换技术对已知说话者的依赖限制,通过创新的分层自适应结构和先进的无监督学习技术,实现了高质量的零样本语音风格转换。这一突破为语音技术的应用开辟了新的可能性,使用户能够轻松地将语音转换为任何所需的风格,无论是否在训练中见过该风格。对于企业用户,HierVST提供了降低配音成本、提升产品个性化程度、拓展多语言市场的机会;对于个人用户,它提供了更丰富的语音表达和交互方式。总体而言,HierVST通过提供灵活、高效、高质量的语音转换能力,为语音技术应用创造了更大的商业价值和用户价值,推动语音交互向更自然、更个性化的方向发展。
用户体验与优势
HierVST为用户提供了卓越的使用体验和显著优势。从用户角度看,该模型操作简便,无需复杂的参数设置即可实现高质量的语音转换,降低了使用门槛。其快速适应能力意味着用户可以在短时间内获得符合期望的转换效果,减少等待时间和调整成本。转换后的语音自然度高,保留了原始语音的内容信息同时准确捕捉目标风格特征,避免了传统语音转换中常见的机械感或失真问题。此外,模型支持多种转换场景(零样本、少样本、跨语言等),满足用户在不同情境下的多样化需求,提供一站式语音转换解决方案。无论是专业用户还是普通用户,都能通过HierVST轻松实现专业级别的语音风格转换,极大提升了语音内容创作和个性化表达的效率与质量。
技术优势
HierVST在技术层面具有多项创新性优势。首先,其分层自适应生成器设计是一大技术亮点,通过依次生成音高表示和波形音频,实现了更精细的语音特征控制和更自然的转换效果。其次,分层变分推理与自监督表示技术的结合,使模型能够从无标注语音数据中有效学习深层语音特征,提高了特征表示的质量和泛化能力。第三,无条件生成策略的引入增强了声学表示中的说话人相关声学能力,使模型能够更好地捕捉和再现不同说话者的独特风格特征。第四,端到端的架构设计简化了系统复杂度,减少了传统流水线式语音转换系统中各模块间的误差累积。最后,模型的模块化设计使其具有良好的可扩展性和可调整性,能够针对不同应用场景进行灵活调整和优化。这些技术创新共同构成了HierVST的核心竞争力,使其在零样本语音转换等挑战性任务中超越现有模型,展现出卓越的性能。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3