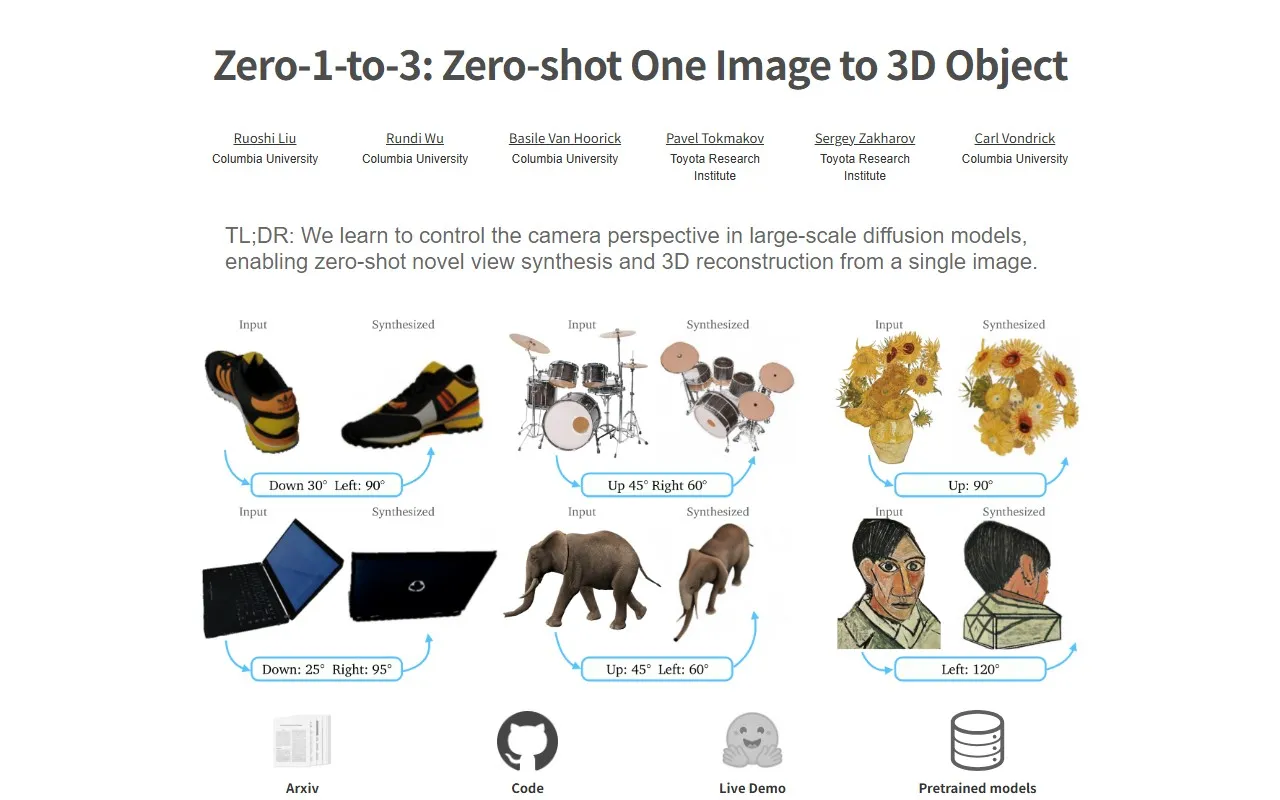
官网介绍
Zero-1-to-3是一个创新的AI框架,全称为"Zero-shot One Image to 3D Object",旨在通过单张RGB图像改变物体的相机视角,实现零样本新视角合成与3D重建。该工具由哥伦比亚大学(Columbia University)与丰田研究院(Toyota Research Institute)联合开发,核心研发团队包括Ruoshi Liu、Rundi Wu、Basile Van Hoorick、Pavel Tokmakov、Sergey Zakharov和Carl Vondrick等学者。
Zero-1-to-3的核心技术基于大规模扩散模型中蕴含的自然图像几何先验,通过训练条件扩散模型学习控制相对相机视角,使模型能够在指定相机变换下生成同一物体的新视角图像。尽管训练数据来源于合成数据集,该模型仍具备强大的零样本泛化能力,可应用于分布外数据集、野生图像(in-the-wild images)甚至印象派绘画等艺术作品。此外,该视角条件扩散方法还可扩展至单图像3D重建任务,通过与NeRF(神经辐射场)结合,从单张图像生成完整的3D模型。

核心功能特点
零样本新视角合成
无需针对特定物体或场景进行额外训练,即可从单张输入图像生成任意指定视角的新图像。模型通过学习相机视角变换规律,能够理解物体的三维结构,即使对于训练数据中未见过的野生图像或艺术作品,也能保持高质量的视角转换效果。
单图像3D重建
支持从单张RGB图像重建完整的3D物体,包括几何结构与纹理信息。通过将视角条件扩散模型与NeRF技术结合,可生成具有精确几何形状和真实纹理的3D模型,并能与Point-E、MCC等现有单视角3D重建模型相比表现出显著优势。
跨模态图像支持
兼容多种输入图像类型,包括真实世界照片、数字绘画(如印象派作品)以及由文本生成图像工具(如DALL-E 2)创建的图像。这一特性极大扩展了模型的应用范围,满足不同场景下的视觉任务需求。
灵活的视角控制
提供量化视角控制(如30度增量旋转)和自定义视角调节两种模式。在线演示支持基础视角选择,本地运行代码则允许用户上传自定义图像并设置任意相机变换参数,实现高度个性化的视角生成需求。
高质量纹理与几何重建
在3D重建过程中,不仅能准确恢复物体的几何轮廓,还能保留原始图像的纹理细节。通过对比实验可见,其重建结果在几何精度和纹理真实性上均优于现有主流单视角3D重建方法。
应用场景
- 计算机视觉研究:作为基础工具支持新视角合成、单图像3D理解等前沿视觉任务的算法开发与验证,为研究者提供高质量的基准结果和对比数据。
- 3D内容创作:帮助设计师、艺术家从单张概念图快速生成3D模型,无需专业3D建模软件操作,大幅降低3D内容创作门槛,提升创作效率。
- 虚拟现实(VR)/增强现实(AR)内容生成:为VR/AR应用提供快速的物体3D化解决方案,支持虚拟场景中物体的多角度展示和交互,增强用户沉浸式体验。
- 数字艺术与设计:允许艺术家将2D绘画、插画转换为可多角度查看的3D艺术作品,拓展数字艺术的表现形式,创造更丰富的视觉体验。
- 游戏开发:辅助游戏美术团队从概念设计图生成游戏内3D资产,缩短角色、道具的建模周期,加速游戏开发流程。
- 文物数字化:通过单张文物照片重建3D模型,实现文物的数字化存档和虚拟展示,降低文物保护与传播的成本,减少实体文物的展示损耗。
- 电子商务产品展示:为电商平台提供商品3D化服务,用户可通过多角度查看商品细节,提升在线购物的体验真实性,减少因视角信息不足导致的退货率。
- 机器人视觉导航:为机器人提供单图像3D理解能力,帮助机器人通过单目视觉感知周围环境的三维结构,提升导航与操作任务的准确性。
优势
Zero-1-to-3的核心优势在于其强大的零样本泛化能力与互联网规模预训练的结合。模型虽训练于合成数据集,却能有效迁移至野生图像、艺术作品等非合成场景,突破了传统3D重建方法对多视图数据或特定领域数据的依赖。此外,其基于扩散模型的视角控制技术创新性地将2D图像生成与3D几何理解融合,无需专门的3D建模模块即可实现高质量3D重建,在算法简洁性和性能表现上均超越现有单视角3D重建模型。同时,工具支持多种输入类型和灵活的视角调节,兼顾学术研究与工业应用需求,具备广泛的适用性和扩展性。
价值总结
Zero-1-to-3的核心价值在于重新定义了单图像到3D内容的转换范式,通过AI技术大幅降低3D内容创作与理解的门槛。对用户而言,其价值体现在三个层面:一是效率提升,无需多视图采集或复杂建模即可快速生成3D内容;二是能力扩展,使非专业用户也能完成专业级3D视觉任务;三是创新赋能,为艺术创作、科研探索等领域提供全新的技术工具,推动视觉内容从2D向3D的跨越发展。无论是研究者、设计师还是企业用户,均能通过该工具提升工作效率、拓展创作边界。
用户体验与优势
Zero-1-to-3提供了友好且灵活的用户体验。在线演示平台支持即插即用的操作,用户可直接上传图像并选择预设视角,快速获取结果;本地代码则允许高级用户自定义参数,满足个性化需求。界面设计简洁直观,无需专业背景即可上手,同时提供详细的文档说明和示例结果,帮助用户理解模型能力边界。此外,模型响应速度较快,即使在有限资源的服务器上也能实现实时视角切换,平衡了性能与可用性,为用户提供流畅高效的使用体验。
技术优势
技术层面,Zero-1-to-3的核心优势在于其创新性的视角条件扩散模型设计。通过在大规模扩散模型中注入相机视角控制信号,模型能够显式学习图像与3D几何之间的映射关系,而非依赖隐式特征推理。这一设计使其在视角变换时能保持物体身份一致性和结构合理性。同时,模型通过互联网规模的图像预训练获取丰富的视觉先验,结合合成数据集的视角标注,实现了从2D图像到3D结构的跨模态知识迁移。此外,与NeRF的结合策略进一步增强了3D重建的精度和稳定性,形成了"视角合成-3D建模"的端到端技术链路,在理论创新和工程实现上均处于行业领先水平。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3