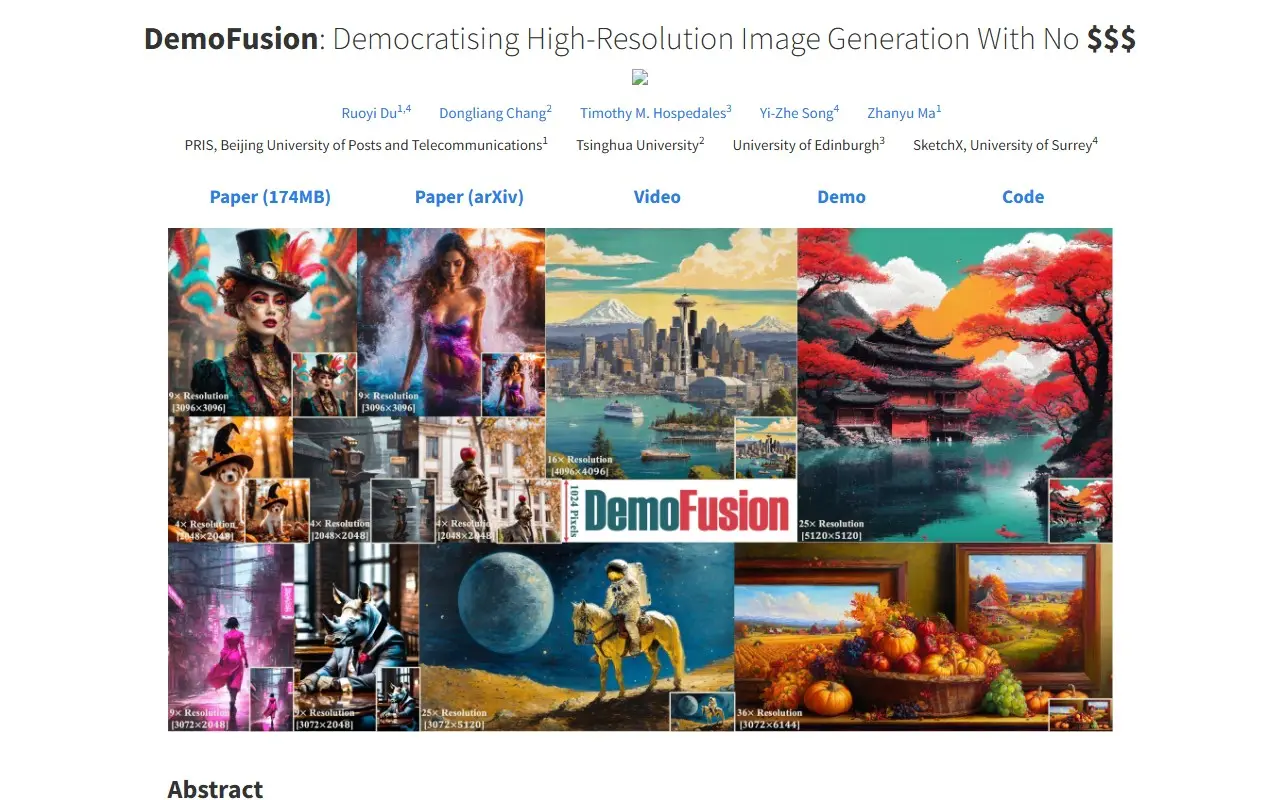
官网介绍
DemoFusion是一个旨在民主化高分辨率图像生成的创新框架,由Ruoyi Du(北京邮电大学)、Dongliang Chang(清华大学)、Timothy M. Hospedales(爱丁堡大学)、Yi-Zhe Song(萨里大学)和Zhanyu Ma(北京邮电大学)联合开发。该框架致力于突破现有生成式人工智能(GenAI)在高分辨率图像生成领域的集中化和付费壁垒,通过扩展开源潜扩散模型(LDMs)的能力,实现无需大量资金投入和复杂训练即可生成高分辨率图像。其核心技术包括渐进式放大(Progressive Upscaling)、跳跃残差(Skip Residual)和扩张采样(Dilated Sampling)机制,能够在单张RTX 3090 GPU上运行,为广泛用户提供可访问的高分辨率图像生成解决方案。

核心功能特点
超高分辨率生成能力
突破传统LDMs的分辨率限制,可将SDXL等模型的生成分辨率提升至4×、16×甚至更高,例如从1024×1024扩展到4096×4096及以上,且无需对基础模型进行任何调优或额外训练。
渐进式生成与预览机制
采用"放大-扩散-去噪"的循环渐进式流程,中间结果可作为"预览",帮助用户快速迭代调整提示词(prompt),提升创作效率和效果。
与现有工具无缝集成
具备无调优特性,可与多种基于LDM的应用无缝结合,例如与ControlNet集成实现可控的高分辨率生成,扩展了工具的适用范围和灵活性。
真实图像放大能力
通过将渐进式流程中的初始阶段输出替换为真实图像的编码表示,可实现真实图像的放大。该过程不同于传统超分辨率,更接近基于真实图像的生成,倾向于符合基础LDM的潜在数据分布。
低硬件资源需求
所有高分辨率图像生成均在单张RTX 3090 GPU上完成,无需高端硬件或大规模计算资源,降低了技术使用门槛。
优于超分辨率的细节表现
相比超分辨率(SR)模型仅提升图像清晰度,DemoFusion能够生成原生高分辨率图像特有的复杂局部细节,避免超分辨率无法提供真实高分辨率内容的局限。
应用场景
- 创意设计与艺术创作:生成超高分辨率艺术作品、插画或概念设计,满足印刷、展览等高质量视觉需求。
- 数字内容制作:为游戏、影视、动画等领域提供高分辨率场景、角色或道具素材,提升视觉表现力。
- 广告与营销:制作高清晰度产品图片、广告海报,增强视觉吸引力,适用于线上线下多渠道展示。
- 学术研究与教育:支持计算机视觉、生成模型等领域的研究,或作为教学工具展示高分辨率生成技术原理。
- 可控高分辨率内容生成:结合ControlNet实现基于草图、姿态等条件的可控生成,适用于建筑设计、时尚设计等需要精确控制的场景。
- 真实图像增强与再创作:对现有照片或图像进行高质量放大与风格化处理,生成符合特定艺术风格的高分辨率内容。
- 快速原型设计:利用渐进式预览功能,快速迭代生成不同风格或细节的高分辨率图像原型,加速创意验证过程。
优势
DemoFusion的核心优势在于其"民主化"高分辨率生成的定位:通过扩展现有开源LDMs,避免了重新训练大型模型的巨额成本,使普通用户无需依赖大型企业的付费服务即可访问高分辨率生成技术。其渐进式流程在保证生成质量的同时,提供了灵活的预览与迭代能力;与ControlNet等工具的兼容性进一步扩展了功能边界;而单GPU即可运行的低资源需求,大幅降低了硬件门槛。相比超分辨率技术,DemoFusion能生成更真实的原生高分辨率细节,解决了传统方法在内容丰富度上的不足。
价值总结
DemoFusion的核心价值在于打破高分辨率GenAI的技术垄断与资源壁垒,为科研人员、创意工作者、中小企业等广泛用户群体提供低成本、高质量的高分辨率图像生成能力。它不仅降低了技术使用门槛(无需专业硬件或大量资金),还通过灵活的集成性和可控性,支持多样化的应用场景,帮助用户高效实现创意表达、内容生产和研究探索,最终推动高分辨率生成技术的普及与创新。
用户体验与优势
用户使用DemoFusion时,可享受到直观且高效的创作流程:渐进式生成的中间预览功能允许快速调整提示词,减少无效尝试;无需复杂的模型调优或参数配置,降低了操作难度;与现有开源工具(如SDXL、ControlNet)的无缝集成,可直接利用用户已熟悉的工作流。此外,单GPU即可运行的特性确保了普通用户的可访问性,而生成结果的高分辨率和细节丰富度则能满足专业级需求,整体提升了用户的创作效率和满意度。
技术优势
DemoFusion在技术层面的核心优势体现在三大创新机制:一是渐进式放大机制,通过"放大-扩散-去噪"循环,以低分辨率结果为初始进行迭代升级,实现分辨率的逐步提升;二是跳跃残差机制,利用前一扩散过程对应时间步的噪声反演表示作为全局指导,增强生成内容的一致性;三是扩张采样机制,改进MultiDiffusion的局部去噪路径,建立全局去噪路径,提升内容的全局连贯性。这些技术均基于现有LDMs设计,无需重新训练模型,在保持轻量级特性的同时,充分挖掘了现有模型的高分辨率生成潜力。


 京公网安备 京ICP备17006096号-3
京公网安备 京ICP备17006096号-3